Scaling TextRazor in the Cloud with Nginx and Lua
We recently opened the doors to the TextRazor beta with a little link on Hacker News. As well as generating some awesome feedback from the community it served as a good load test on the backend, peaking at around 200 concurrent requests coming from the demo page and through the API. Now things have quietened down a bit I figured it's a good time to talk a bit about how we handle routing, scaling and load balancing. Hopefully it'll be of interest to anyone building a similarly resource intensive API.
The "Cloud"
Our aim was to build a realtime service that could effortlessly handle the heavy concurrent, bursty loads that are typical of text mining and natural language processing applications. At first glance this seems like an ideal workload for the cloud, but doing the maths things aren't so clear cut. TextRazor needs large multicore machines with 32gb of RAM. We found the extra-large EC2 instances significantly underperform the equivalent consumer-grade dedicated hardware (i5 / i7s) in terms of raw throughput. Large EC2 instances are also very expensive compared to colocation/dedicated servers, up to 6 or 7x the price (though you can bring this down with reserved instances). We were hesitant to ditch the cloud and go bare metal all the way since it's nice to be able to spin up extra workers to handle load spikes, rollout updates, run tests, and make use of all the other goodies Amazon have to offer.
We therefore came up with a hybrid approach, keeping a selection of big dedicated servers available for the regular workload and dynamically adding extra instances from EC2 on demand. This means we get the best of both worlds - high performance/low cost for the baseline usage levels, with the "cloud" available when it's needed. This also means that when EC2 catastrophically falls over (not unheard of unfortunately) we can manually reroute to the dedicated servers via DNS.
We run the main routing logic on EC2, with dedicated servers in various locations on the East Coast. Latency was initially a worry, but it turns out there are several colo facilities and dedicated hosts with acceptable pings from US-East (Virginia). Pings from Virginia to the other major datacentres look a bit like:
- NY/NJ - 10ms
- Chicago - 20ms
- Dallas - 35ms
- LA - 70ms
- Europe - 100ms
For our purposes anywhere on the East Coast is acceptable.
Custom Routing
Routing requests between EC2 and geographically distributed servers is a non trivial problem. Ideally we'd like a load balancing algorithm to take into account the load on each server, size of the server, a user's plan, the language of the request and various other factors.
Unfortunately the built in AWS Elastic Load Balancer can only route to EC2 instances and doesn't seem to offer much more than round robin routing (bit disappointing given all the stats Amazon collect from Cloudwatch). This can cause problems for APIs like ours - since a single request is parallelized across all cores and can legitimately take anywhere between 10ms and 5000ms, it's easy to get into a state whereby multiple long requests happen to be queued up behind each other.
Instead of relying on a third party load balancer we use Nginx to balance in software on EC2. To remove the single point of failure we can add extra router instances, place them behind an AWS load balancer, and shard requests between them based on a consistent hash of the API key. The second layer then transparently routes to both our dedicated servers and cloud instances, all with only a few ms of additional latency. The system looks a bit like this:
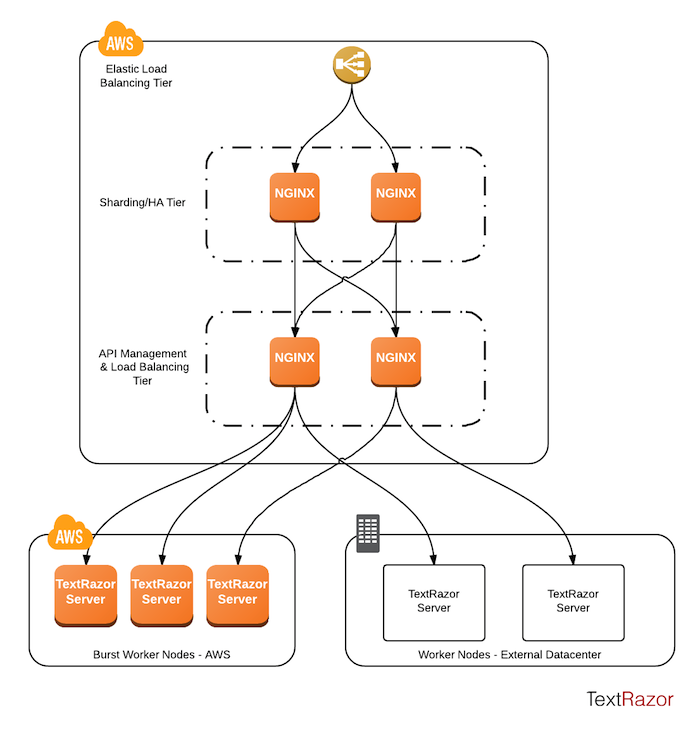
Omitted here are MongoDB servers for persisting user data, and the website which runs completely separately on Heroku.
The "API Management & Load Balancing Tier" is where most of the routing magic happens. Each node is aware of the state of its cluster, including the concurrent use and health of each backend. For high availability we need both Nginx tiers. API usage information is cached in memory in the router to avoid costly db lookups, so we want to make sure a single user's requests always hits the same router where possible. However should that node go down the downstream Nginx and Amazon load balancer can quickly detect the failure and route elsewhere.
Lua
We control our own routing logic using a version of Nginx scripted with Lua via the ngx_lua plugin. Lua is a lightweight scripting language with easy to pick up syntax and semantics, and is well worth checking out. The module doesn't come as part of Nginx by default, but it's simple to build a patched version with it. Alternatively you can just grab the openresty distribution, which contains this module as well as a bunch of other useful stuff. With luajit the plugin is blisteringly fast, and as long as you use the built in APIs and ngx.location.capture it's trivial to write code that's non blocking on IO. This means a single ngx_lua router with simple callback-free code can easily handle thousands of concurrent requests.
Almost all aspects of the web server can be customised with Lua. TextRazor uses it for the aforementioned routing logic, as well as handling validation of API keys, monitoring concurrency, health checking backends, and filtering bad requests.
Example
Lua can be embedded directly in your nginx.conf, or it can be imported from external files. Here I'll walk you through an example nginx.conf that's a much simplified version of ours. The aim is to do least connection routing amongst a variable group of backend servers (Nginx can actually handle static leastconn routing itself these days, this is meant to give you an idea of what's possible). The backend servers are updatable by POSTing a JSON list of addresses to the /admin/set_backends/ endpoint (from the same machine for the obvious security reasons). We use something similar to keep the list of healthy backend servers up to date using a supervisor process. This is just a simple Python script that keeps track of the dedicated servers and is integrated with the rest of the EC2 APIs with the Boto library to auto discover new healthy workers.
We start off with some familiar Nginx boilerplate:
user www-data;
pid /var/run/nginx.pid;
worker_processes 4;
error_log logs/error.log;
events {
worker_connections 2024;
}
http {
# It's useful to log the user's API key in the access logs to help track down any bad requests.
log_format hitlog '$remote_addr - $api_key [$time_local] '
'"$request" - $request_length $status $bytes_sent -> $backend_server $request_time seconds ($upstream_response_time upstream)';
lua_package_path '/usr/local/openresty/lualib/?/init.lua;;'; # Tell nginx where to find the lua standard library
lua_shared_dict upstream_curr_requests 10M; # Map from upstream address to the current number of outstanding requests. This is a shared memory map provided by ngx_lua with similar interface to a standard Lua table.
#init_by_lua_file 'path/to/some/lua.file'; # Any of these Lua methods can be replaced with an external file, making things much cleaner.
server {
listen 80;
Next we'll add a method for setting the active list of upstream worker nodes:
location /admin/set_backends/ {
allow 127.0.0.1; # Only allow local connections
deny all;
content_by_lua '
ngx.req.read_body() -- ngx_lua won't parse the request body unless needed, tell it to do so here.
-- Parse the body, which should be a JSON list of new upstream servers
local body_data = ngx.req.get_body_data()
local cjson = require "cjson"
local new_upstream = cjson.decode(body_data)
local upstream_curr_requests = ngx.shared.upstream_curr_requests
-- Fetch the current active backend servers with an arbitrary limit (yes, this should not be a magic number).
local upstream_curr_requests_keys = upstream_curr_requests:get_keys(10000)
-- First add the new backends
for upstream, _ in pairs(new_upstream) do
upstream_curr_requests:add(upstream, 0)
end
-- Then delete the old ones
for _, upstream in pairs(upstream_curr_requests_keys) do
if new_upstream[upstream] == nil then
upstream_curr_requests:delete(new_upstream)
end
end
';
}
Now for the main endpoint. Here we've set a Lua script for the "access" Nginx phase, responsible for choosing an appropriate backend and validating/authenticating a user's request. We also add a custom log_by_lua, called after the response has been retrieved from upstream.
location / {
client_body_buffer_size 1M; # Buffer full requests in memory so we can read the apiKey out of the body.
# Set some nginx variables we'll later set in lua. By exposing these variables to nginx we can use them for routing and logging outside of Lua.
set $best_upstream "";
set $api_key "";
access_by_lua '
ngx.req.read_body()
local args = ngx.req.get_post_args()
local api_key = args["apiKey"]
if api_key == nil then
ngx.status = ngx.HTTP_BAD_REQUEST
ngx.say("Request is missing apiKey param.")
return ngx.exit(ngx.HTTP_BAD_REQUEST)
end
-- Perform a bunch of other request validation and user authentication steps here.
ngx.log(ngx.INFO, "Processing request from " .. api_key)
local upstream_curr_requests = ngx.shared.upstream_curr_requests
local upstream_curr_requests_keys = upstream_curr_requests:get_keys(10000)
local best_upstream = ""
local lowest_connections = 99999
-- Iterate over the candidate upstream servers, work out the best for this request.
-- For this example we'll just do least connection routing, but the sky's the limit in what's possible here.
for _, upstream in pairs(upstream_curr_requests_keys) do
local curr_connections = upstream_curr_requests:get(upstream)
if curr_connections == nil then
best_upstream = upstream
lowest_connections = 0
elseif curr_connections < lowest_connections then
best_upstream = upstream
lowest_connections = curr_connections
end
end
upstream_curr_requests:incr(best_upstream, 1)
ngx.var.api_key = api_key
ngx.var.best_upstream = best_upstream
';
log_by_lua '
-- We've got a response from upstream, update the current usage stats for that server.
if ngx.var.best_upstream ~= nil then
ngx.shared.upstream_curr_requests:incr(ngx.var.best_upstream, -1)
end
';
proxy_pass http://$best_upstream; # Proxy to the upstream server set previously by lua
}
}
}
ngx_lua can be used as a fully fledged web app framework, with an ever growing list of helpful modules for MySQL, MongoDB, Redis, etc. Even though it's still relatively young, it's odd ngx_lua hasn't received much love from the community. It's a great bit of technology, and I'm sure with a bit of evangelising it could see the adoption it deserves.
Tweet